# Tutorial: Simple Dashboard
In this tutorial, we'll be working with Speckle data and using it to create a super simple dashboard. We'll be receiving geometry from a stream, updating the data, and using it to do some calculations and simple plots using Plotly and Dash.

We will assume you have general knowledge of Python and Speckle. If anything trips you up, have a look back at the Python examples or the Speckle Concepts.
If you want to follow along with the code, the repo for this project can be found here (opens new window).
# Receive Objects From The Server
If you've already been through the Python examples, you'll already know how to receive objects from the server. As a refresher, you'll need to create a SpeckleClient which serves as your entry point to the API. We then authenticate this client using a token from a local account. If you haven't used the Manager to add a local account, you can go to your-server.com/profile and create a Personal Access Token to use here. We'll then use this client to get the commit we're interested in.
In this case, we're going to be looking at this twisty building Alan generated in Grasshopper and send to Speckle using the Grasshopper Connector. It has 10 levels split into separate objects each containing fields for facades, columns, banisters, and floor slabs.
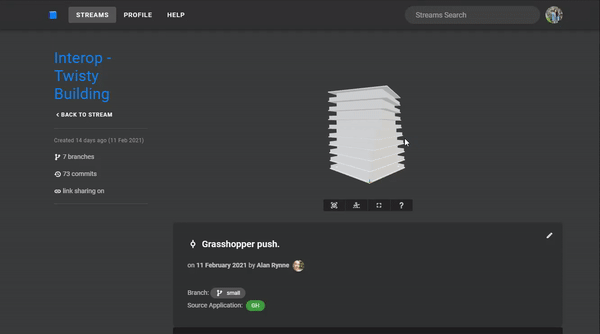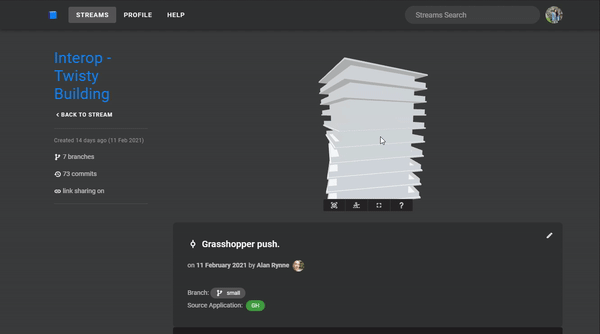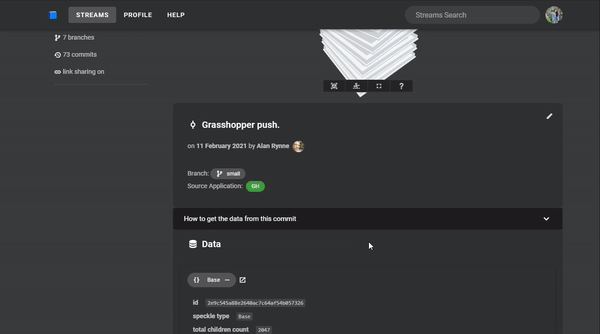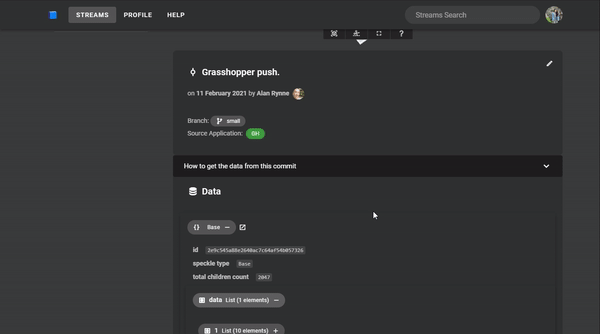
The snippet below shows how you would authenticate the client, get the commit we're interested in, and use a server transport to receive the commit object.
from specklepy.api import operations
from specklepy.api.client import SpeckleClient
from specklepy.api.credentials import get_default_account
from specklepy.transports.server import ServerTransport
# create and authenticate a client
client = SpeckleClient(host=HOST)
account = get_default_account()
client.authenticate_with_account(account)
# get the specified commit data
commit = client.commit.get(STREAM_ID, COMMIT_ID)
# create an authenticated server transport from the client and receive the commit obj
transport = ServerTransport(client=client, stream_id=STREAM_ID)
res = operations.receive(commit.referencedObject, transport)
# get the list of levels from the received object
levels = res["data"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Update Existing Objects
Now that we've received this building from Grasshopper, let's make some modifications. The data has already been structured nicely into a list of Base objects each representing a level. Each level has attributes containing that level's facade, columns, banister, and floor slab.
{
"id": "idfcaf8b9e145241dsdfa915885d87cda2",
"speckle_type": "Base",
"data": [
{
"id": "ide6acabd37e865ce87a5sdf444d733877",
"speckle_type": "Base",
"@facade": [ { ... }, ... ],
"@columns": [ { ... }, ... ],
"@banister": { ... },
"@floorSlab": { ... }
},
{
...
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Let's say we want to do some estimated embodied carbon calculations. However, currently no material information has been added to the elements in the stream. We can add this ourselves and update the stream for the rest of the team.
# Subclassing Base
To do this, let's create classes for each material and add these materials to a "material" attribute on each object within the stream. Obviously, this is a bit of an over the top example. It would be more efficient to just add a string attribute to each object that indicates the material, then look up the material properties from a database when running the calculations. However, I want to have some fun here and show you some of the cool things you can do with the Base class!
Let's start with defining our materials as Base subclasses. This ensures they'll be serialised correctly and that they'll be picked up by the Base type registry. We can then create a mapping for each element type name to the speckle_type of the corresponding material class. The speckle_type is prepopulated by the class and defaults to the class name.
# density (kg/m^3) and embodied carbon (kg CO^2/kg) estimates
# from https://www.greenspec.co.uk/building-design/embodied-energy/
class Concrete(Base):
density: str = 2400
embodied_carbon = 0.159
class Glass(Base):
density: str = 2500
embodied_carbon = 0.85
class Steel(Base):
density: str = 7800
embodied_carbon = 1.37
MATERIALS_MAPPING = {
"@floorSlab": "Concrete",
"@banister": "Glass",
"@facade": "Glass",
"@columns": "Steel",
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
We can now write a function that iterates through all the members of a level and adds a material if it exists in our mapping.
def add_materials_data(level: Base) -> Base:
# first, get all the attribute names
names = level.get_member_names()
# then iterate through them to check if they exist in our mapping
for name in names:
if name not in MATERIALS_MAPPING.keys():
break
# if they do, use this class method to get the class and init it
material = Base.get_registered_type(MATERIALS_MAPPING[name])()
# now we can add a `@material` attribute dynamically to each object.
# note that we're making it detachable with the `@`
prop = level[name]
if isinstance(prop, Base):
prop["@material"] = material
elif isinstance(prop, list):
for item in prop:
item["@material"] = material
return level
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Note that we've added a detached dynamic attribute called @material to each element we are interested in. We've marked it as detachable (prepended with an @) so we don't store hundreds of copies of the same materials classes in this stream. Each instance of each materials class in our case is the same, so we only need to store each once. However, we want to reference them within multiple elements. Using a detachable attribute is the solution! You get a reference for the correct material object in each element, but you only store unique objects (in our case, one instance of each material class) in the stream.
# Sending to the Stream
We can now use the add_materials_data() method we wrote to update all the levels in the stream and send these updated levels back. Let's add on to what we've already written.
To send our updated building, we'll need to create a parent Base and place our list of nested levels inside this parent. To keep things consistent, we'll be adding them to a field called data.
from specklepy.objects import Base
# add the materials data to our levels
levels = [add_materials_data(level) for level in levels]
# create a base object to hold the list of levels
base = Base(data=levels)
2
3
4
5
6
7
We'll then use operations.send() to send this object to the stream, then use client.commit.create() to commit our changes to the stream. If we want to send to a new branch, we can do so by first creating one using client.branch.create(stream_id, name, description). The snippet below shows this full process.
# recap from earlier
client = SpeckleClient(host=HOST)
account = get_default_account()
client.authenticate_with_account(account)
commit = client.commit.get(STREAM_ID, COMMIT_ID)
transport = ServerTransport(client=client, stream_id=STREAM_ID)
res = operations.receive(commit.referencedObject, transport)
# get the list of levels from the received object
levels = res["data"]
# add the materials data to our levels
levels = [add_materials_data(level) for level in levels]
# create a branch if you'd like
branch_name = "🐍 demo"
branches = client.branch.list(STREAM_ID)
has_res_branch = any(b.name == branch_name for b in branches)
if not has_res_branch:
client.branch.create(
STREAM_ID, name=branch_name, description="new stuff from py"
)
# create a base object to hold the list of levels
base = Base(data=levels)
# and send the data to the server and get back the hash of the object
obj_id = operations.send(base, [transport])
# now create a commit on that branch with your updated data!
commid_id = client.commit.create(
STREAM_ID,
obj_id,
branch_name,
message="add detached materials",
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
If we go back to the web to look at the stream, you'll see your newest commit. The geometry should look the same since this hasn't been modified, but stepping into the data will show you the new material attribute. As you can see in the gif below, the id of the Concrete object is the same on different floor slabs since the attribute is detached and the objects are identical.
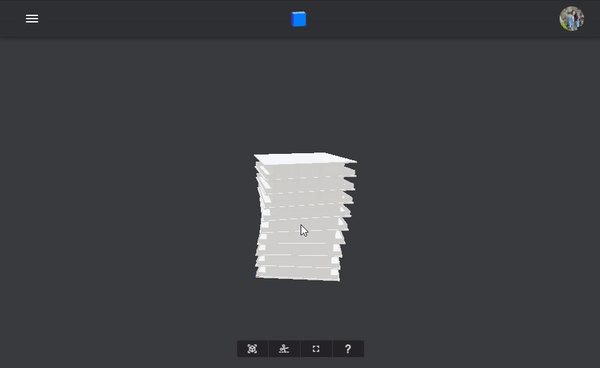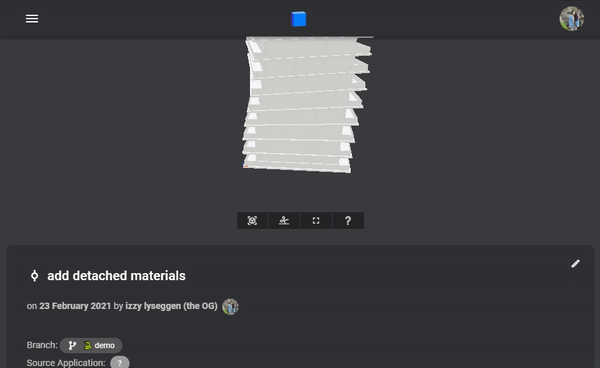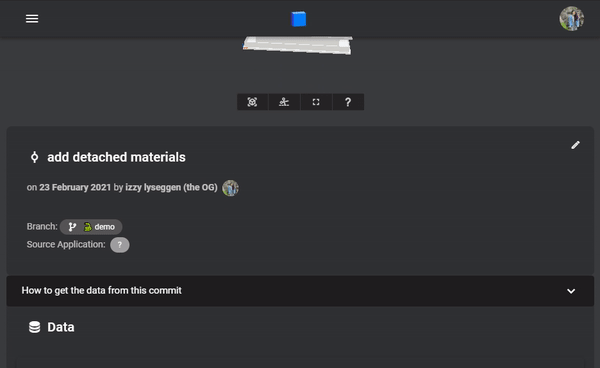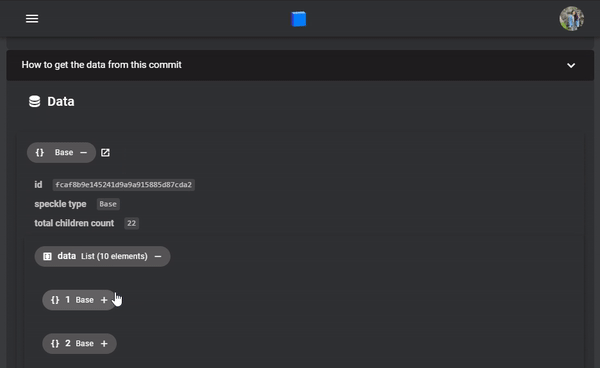
Now that you've sent your changes to the server, anyone you're collaborating with will also be able to pull down your changes and use these updated elements with materials data!
# Do Cool Stuff
We've now seen how we can receive, work with, and send data from Python just like you can with any of the other SDKs and connectors. Great, now we can use that data to make something cool! Let's plot the data using plotly (opens new window) and display it on a simple page using dash (opens new window). I won't go into too much detail on using the libraries themselves, but most of the plotting code has just been modified from the boilerplate and examples in their docs.
To start, let's extract some existing data from the objects and plot them. Each geometry object we're interested in has a Vertices attribute containing a list of points. Let's plot the vertices of the floor slabs and columns on a 3D scatter plot. To do this, we'll need to construct a pandas data frame with the values we are interested in by iterating through the levels.
import pandas as pd
def construct_points_df(levels: List[Base]):
# initialise a pandas data frame
df_vertices = pd.DataFrame(columns=("x", "y", "z", "element"))
vertices = []
for level in levels:
# add column vertices
columns = level["@columns"]
for column in columns:
points = column.Vertices
for p in points:
vertices.append({"x": p.x, "y": p.y, "z": p.z, "element": "columns"})
# add floor slab vertices
floorslab = level["@floorSlab"]
points = floorslab.Vertices
for p in points:
vertices.append({"x": p.x, "y": p.y, "z": p.z, "element": "floorSlab"})
return df_vertices.append(vertices)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Now we can just pass that data frame into the plotly express scatter_3d method and show() the figure.
import plotly.express as px
df_vertices = construct_points_df(levels)
fig = px.scatter_3d(
df_vertices,
x="x",
y="y",
z="z",
color="element",
opacity=0.7,
title="Element Vertices (m)",
)
fig.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Plotly plots have interactivity built in, so this is all the code we need to produce this 3D scatter plot.

Next, let's make use of the material properties we added to each of the stream objects. Let's calculate the mass and embodied carbon for each element type in one level and construct a data frame with the results.
def construct_carbon_df(level: Base):
data = {"element": [], "volume": [], "mass": [], "embodied carbon": []}
# get the attributes on the level object
names = level.get_dynamic_member_names()
# iterate through and find the elements with a `volume` attribute
for name in names:
prop = level[name]
if isinstance(prop, Base):
if not hasattr(prop, "volume"):
break
# if it has a volume, use the material attribute to calculated
# the embodied carbon
data["volume"].append(prop.volume)
data["mass"].append(data["volume"][-1] * prop["@material"].density)
data["embodied carbon"].append(
data["mass"][-1] * prop["@material"].embodied_carbon
)
elif isinstance(prop, list):
if not hasattr(prop[0], "volume"):
break
data["volume"].append(sum(p.volume for p in prop))
data["mass"].append(data["volume"][-1] * prop[0]["@material"].density)
data["embodied carbon"].append(
data["mass"][-1] * prop[0]["@material"].embodied_carbon
)
data["element"].append(name[1:]) # removing the prepending `@`
return pd.DataFrame(data)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Using this data frame, we can use the plotly express pie() and bar() methods to create some lovely plots.
# take the first level from our levels list and construct a data frame
df_carbon = construct_carbon_df(levels[0])
# let's add them all to a dict to keep the together
figures = {}
figures["volumes"] = px.pie(
df_carbon,
values="volume",
names="element",
color="element",
title="Volumes of Elements Per Floor (m3)",
)
figures["carbon bar"] = px.bar(
df_carbon,
x="element",
y="embodied carbon",
color="element",
title="Embodied Carbon Per Floor (kgC02)",
)
figures["carbon pie"] = px.pie(
df_carbon,
values="embodied carbon",
names="element",
color="element",
title="Embodied Carbon Per Floor (kgC02)",
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
The last thing we're going to do is add the figures to a dash app. To do this, we are simply taking the boilerplate dash layout (opens new window), replacing the sample figure with our own figures, and adding some custom css in /assets/style.css.
Now all that's left is to run app.py and head to http://127.0.0.1:8050/ (opens new window) to see your amazing plots.
# Conclusion
And voila - you've created the basis for a dashboard powered by your Speckle data! This is just a simple start, and we'd love to see the interesting things you build with Speckle. If you have any questions or want to share what you've been hacking, start a conversation on our forum (opens new window)
For reference, all the code for this project can be found here (opens new window).
← Examples Introduction →