# Architecture
Quick Summary
By reading this post you will get a comprehensive understanding of the low level fundamentals of Speckle. You'll be ready to make the most out of what Speckle has to offer.
You will know how you could create your own backend to Speckle, how data flows and how you can control those flows, how data is stored, as well as how applications interact with Speckle and can use it as a data persistence framework.
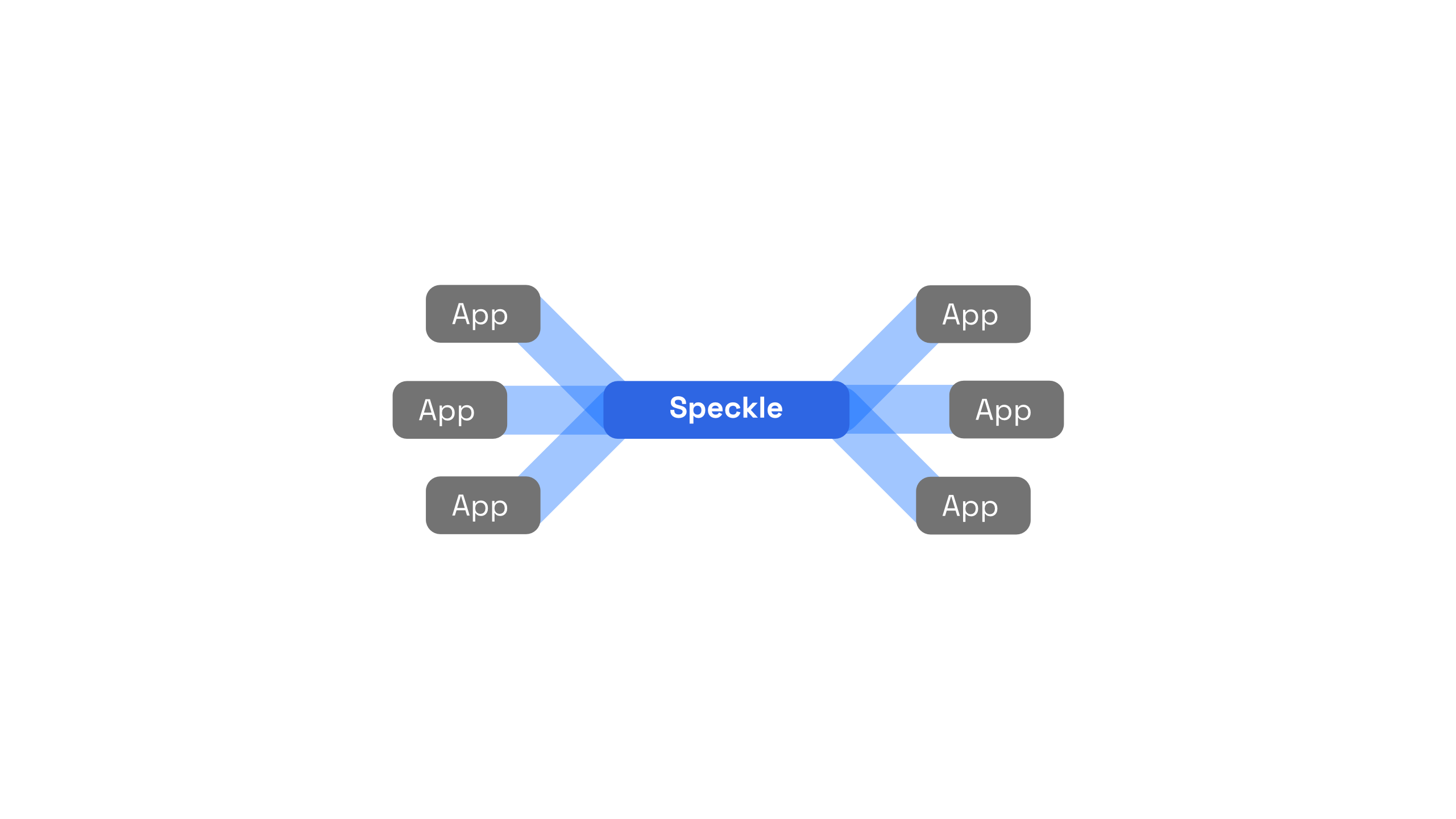
Speckle is the open source data platform built for the AEC industry. What does this platform do? Put simply, Speckle consists of a set of infrastructural components needed to store and retrieve data.
# Data
Some of these applications are authoring tools - such as Revit and Rhino - and other applications are SPA web apps, other more fully fledged backend apps - including scripts, serverless functions, etc.
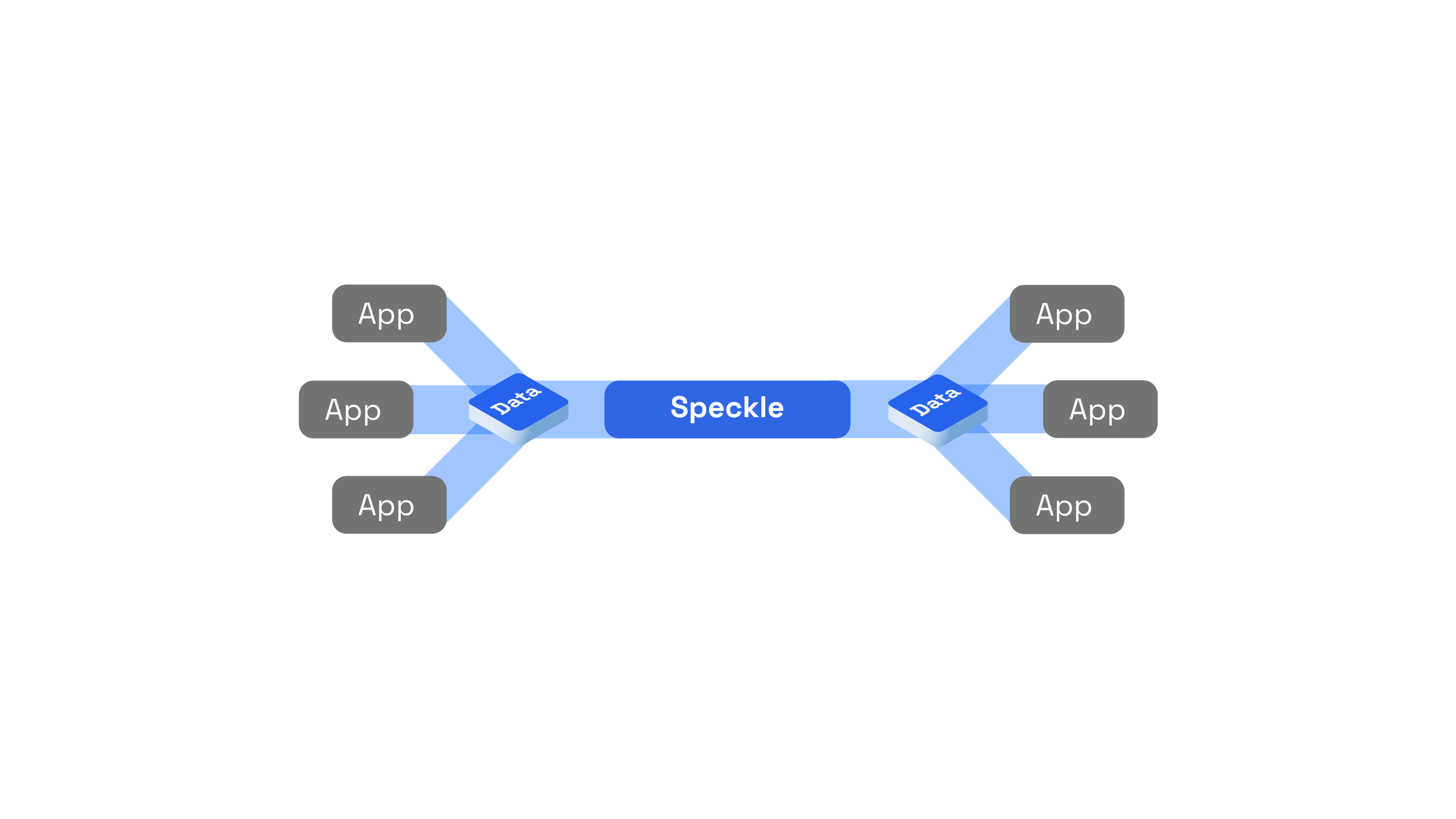
These applications, in order to talk to each other and make sense of the data they are consuming, need to speak a common language. The design and principles of this common language are centred around composability and extensibility, and not around completeness. This makes Speckle much more approachable than, for example, IFC.
Extra reading
Here's an article through how we implemented this approach in our .NET SDK.
# Kits
A Speckle Kit is, essentially, the definition of a common language: a schema. Moreover, a Speckle Kit also contains the translation routines to and from an application's native object model to the kit's schema. Kits are "hot-swappable": Speckle comes with one by default which delivers the core of our interoperability capabilities. Nevertheless, anyone can define their own kit to serve their purpose.
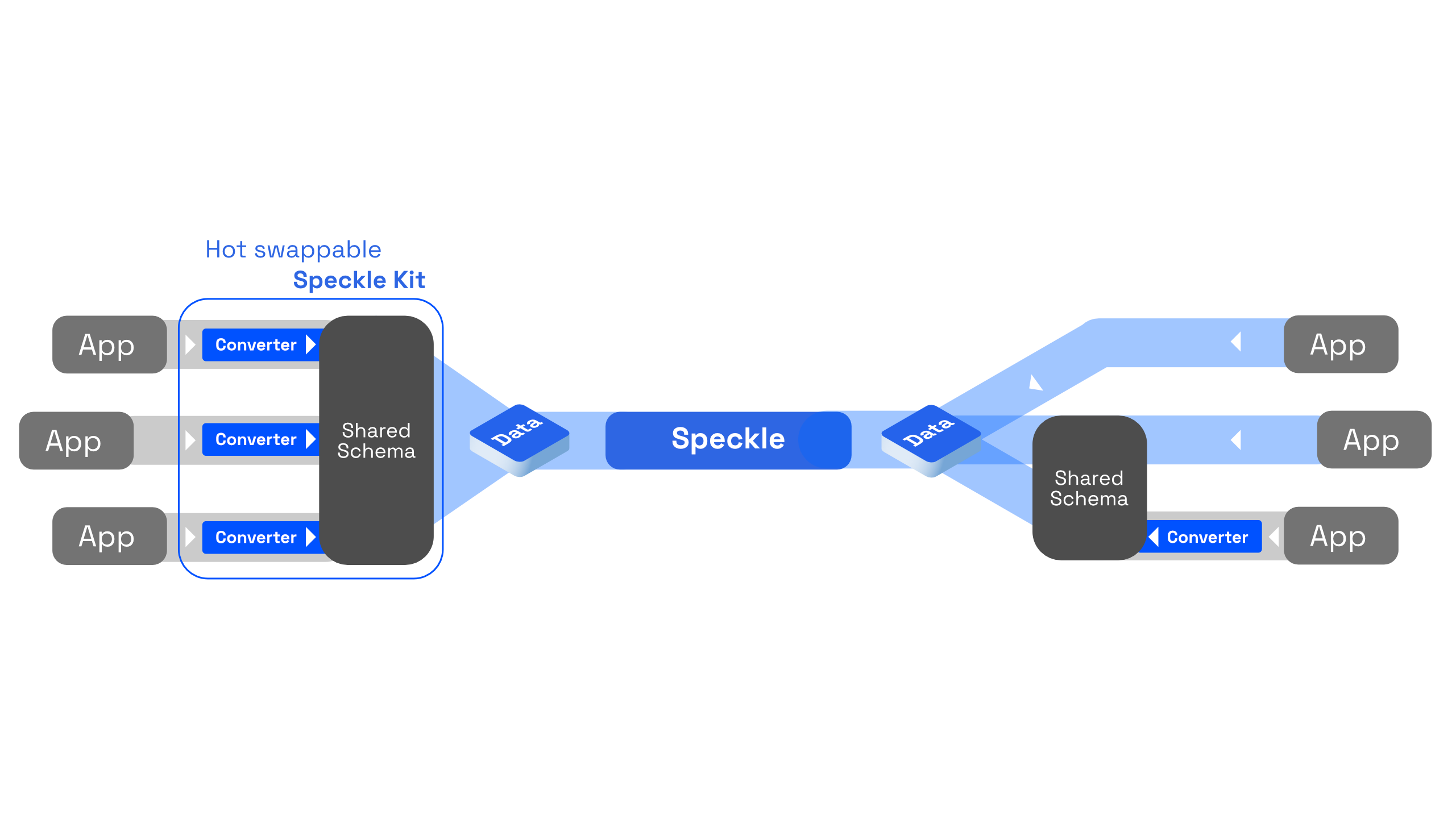
Existing authoring applications, such as Rhino, Revit, Autocad, send and receive data from and to Speckle by passing it through the conversion routines of a given kit. This is handled through Connectors. Connectors are plugins that integrate within these host applications (e.g., the Rhino Connector) and allow end-users to select the data they want to send to Speckle, and, behind the scenes, convert it and, lastly, transport it to Speckle.
Extra Reading
Read more about Kits here. If curious, you can also follow up with the discussion on our forum (opens new window).
We also have a guide on how to write your own Connector - check it out!
Other applications do not necessarily need to do so: they can directly use a kit's schema - or simply use objects that respect the few low-level constraints that Speckle needs to serve its purpose. These aspects are described below in Serialisation & Structure. Next, we're going to discuss how the serialisation layer interacts with the storage layer.
# Serialisation & Storage
Once Speckle data is translated or directly created, it needs to be serialised and, lastly, stored. In reverse, data needs to be retrieved from the storage layer and de-serialised to a memory representation that can be used by the application it was received in (either converted back to host application representations, or consumed by the business logic of the app. During the process of serialisation, Speckle also needs to decompose objects into their constituent parts; similarly, it needs to re-compose them during the de-serialisation process.
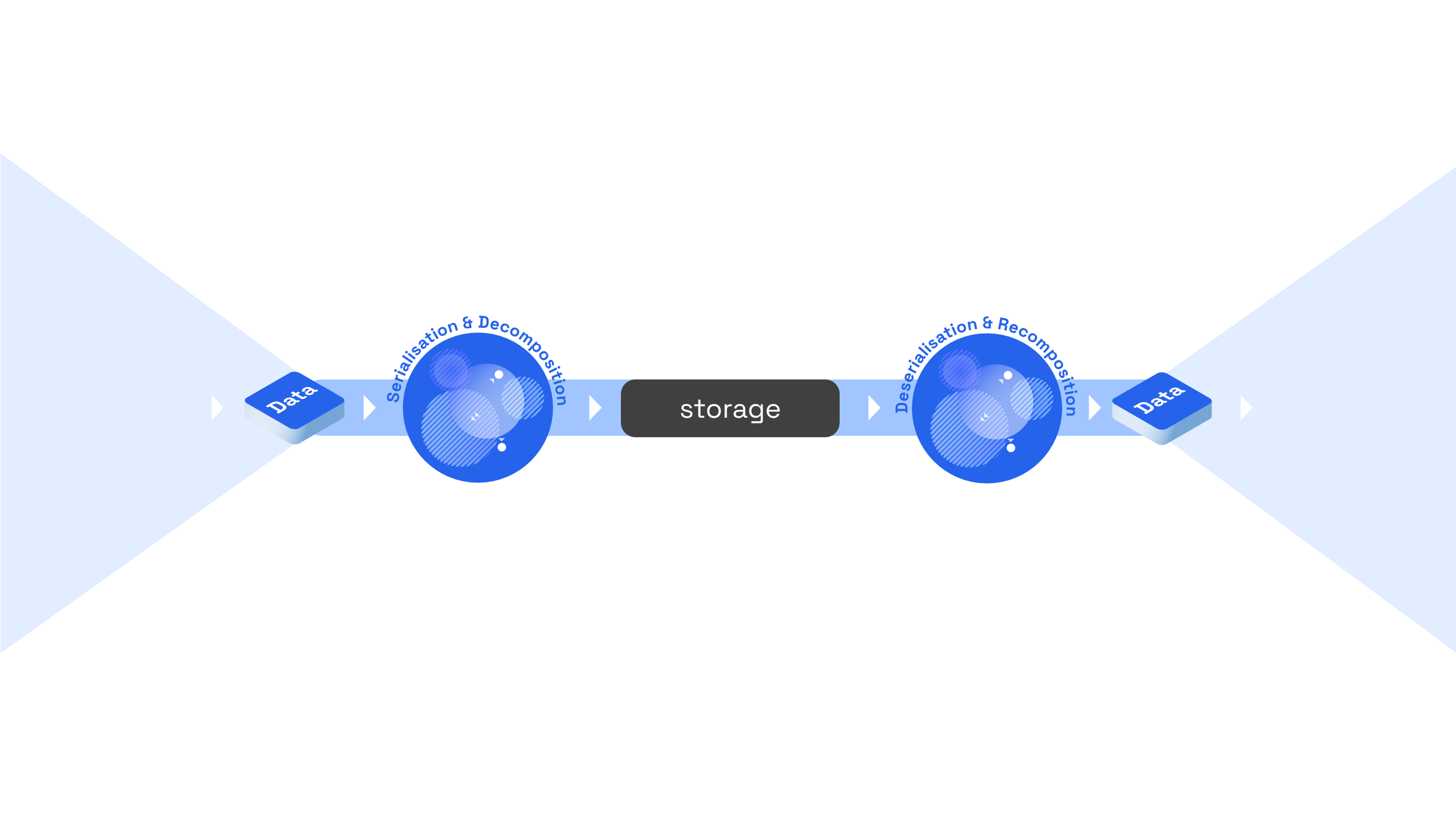
Before we dive deeper into Speckle's decomposition and re-composition procedures, we will first take a look at how the storage layer is handled in Speckle and the flexibility it offers.
# Transports
Different storage systems have various characteristics that make them better (or more ill) suited for different scenarios. This is why, rather than employ a unique storage system, Speckle uses an intermediary abstraction layer: transports. A transport defines the way Speckle writes to, and reads from, a given persistence layer.
![]()
One such transport is the Speckle Server Transport. Another transport is an SQLite Transport. Speckle comes with a couple of other transports too: a MongoDB transport, an In-Memory Transport, as well as a Disk Transport. Other transports, such as an S3 transport, a MySQL transport could easily be developed.
The Disk Transport writes and reads your Speckle data from files in a location you specify, while the SQLite Transport does the same, but backed by a SQLite database. For example, the latter is used extensively throughout our Connectors as a local cache so as to reduce the dependency on a high-latency transport, namely the one for the Speckle Server.
Transports offer developers low-level flexibility in developing, essentially, their own custom back-ends to Speckle, or pushing data to other systems that can do different things - even a whole new Speckle Server.
Moreover, send operations are no longer restricted to one single location: Speckle allows you to send data, in parallel, to multiple transports. For example, data can be sent to two different Server Transports at the same time, one being an internal server and one being an external one - a different stakeholder involved in the process.
Alternatively, a plugin based on Speckle could be developed that acts much more like git, writing data to a local folder that resides right next to the source file itself. This enables, in whatever configuration you see fit, a local only usage of Speckle, with pushing to remotes being a secondary, optional operation.
Extra reading
A work-in-progress guide on how to write your own transport can be found here.
# Serialisation & Structure
Before data can be persisted to a storage system, it needs to be serialised. Serialisation is the process by which an object is converted into a state that can be stored or transmitted, and be reconstructed later from (deserialisation).
Objects are, by their nature, structured data. The object graph and, implicitly, its structure, gives it meaning. Serialising a whole object graph in a naive way would result into a large blob which would be difficult to work with, and exclude certain workflows - such as reading just subsets of the graph, or individual objects - without deserialising the whole structure first. Storage systems, such as databases, work best with what we call "flat" data: individual rows, each corresponding to a given object.
Speckle solves this structural impedance mismatch by deconstructing an object into its individual constituent parts during the process of serialisation. These individual objects are then sent for storage to any given transports.
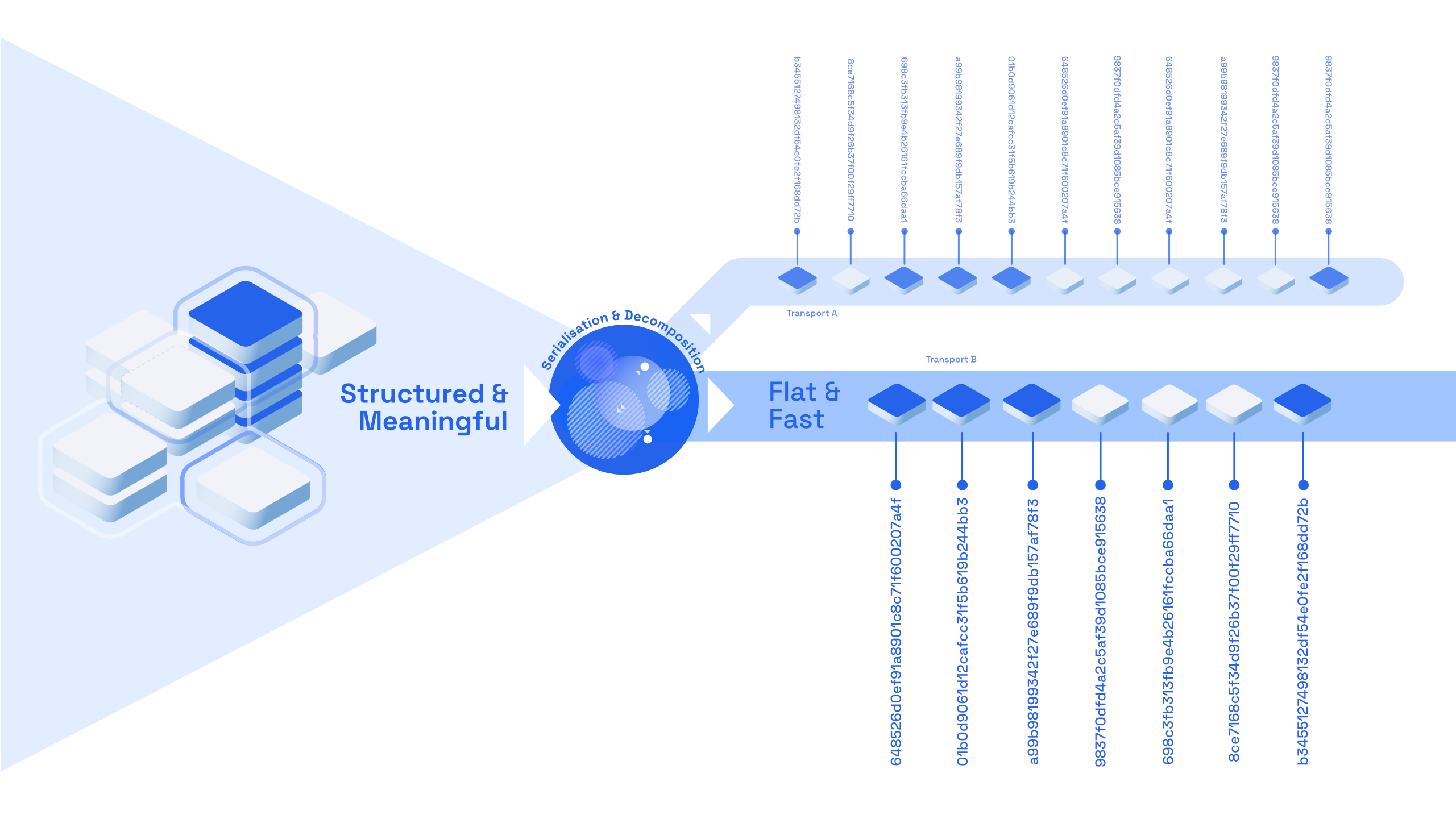
Each object, when serialised, gets a unique id which is generated by hashing its value. This means that all objects are immutable: if they change throughout their lifecycle, they get a new hash.
These object hashes are also used to assemble, for each individual object, its internal graph references. What this means, essentially, is that each Speckle object contains the information needed for reconstructing its full graph of descendants - alongside its own data.
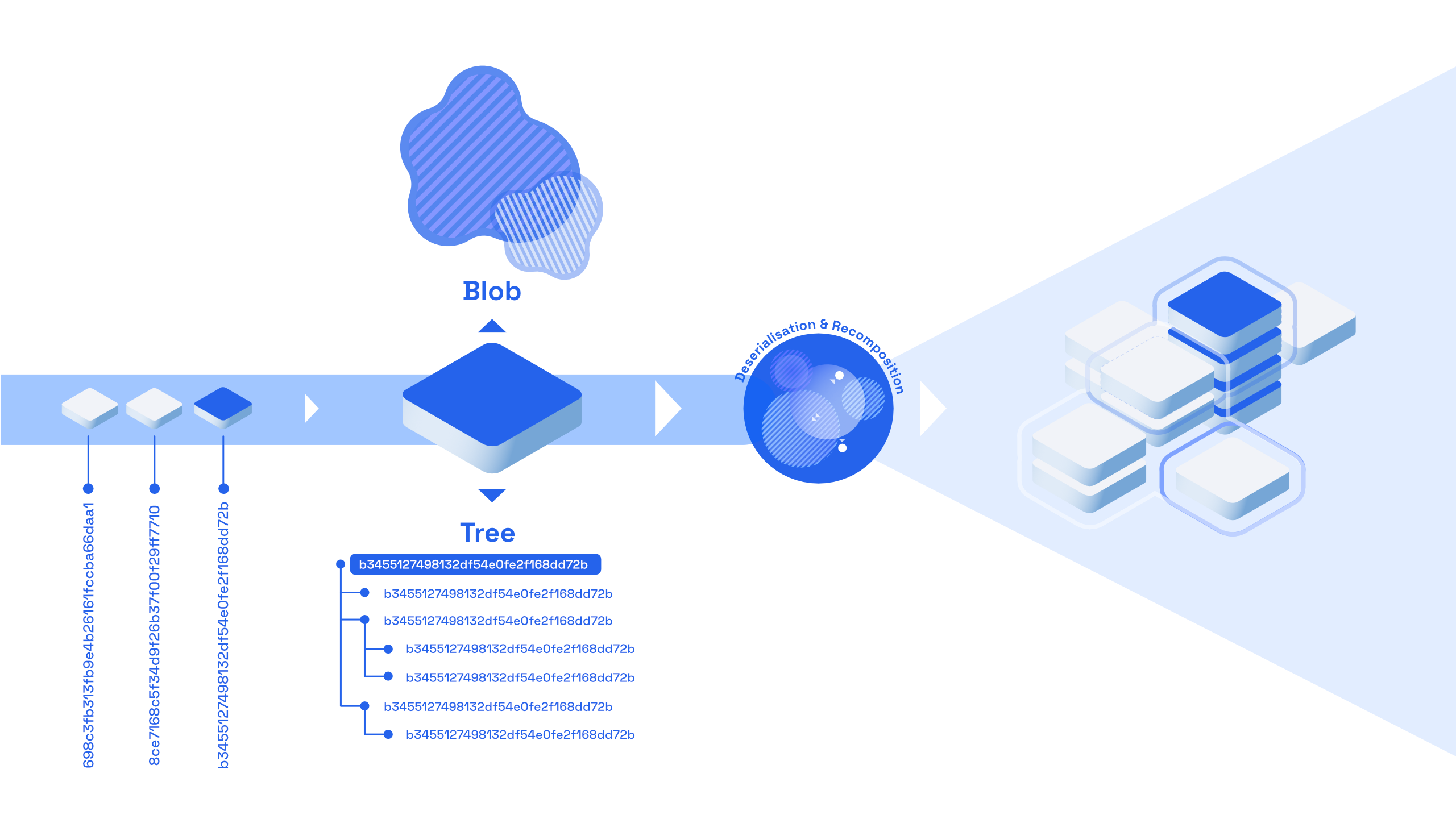
At the heart of git there are two types of objects: trees and blobs. Blobs represent the files themselves, and trees represent the file structure. Objects in Speckle are, essentially, both a tree and a blob at the same time - the "blob" being the value of the object itself, and the tree representing its object graph. While git sources its tree from the folder structure of your project, Speckle sources it from the object graph itself.
When deserialising data, Speckle reconstructs it at the same time. This means that data can reside and make use of the upsides of storage systems such as relational databases, while at the same time, developers are not constrained as to how they structure it and can continue working with it freely inside their applications.
Another important note is that Speckle uses JSON as the native serialisation format for the object "blobs". JSON is a format that is widely used and has plenty of tooling in various languages, and, most importantly, it is both machine and human readable.
Extra Reading
Speckle's decomposition api is described in more depth here.
# Wrapping Up
This post covered the low level building blocks of Speckle and how they work together. The key points and concepts that we've covered are:
- How apps interact with Speckle, and how data can be translated between them: either directly, or through Speckle Kits.
- How data gets serialised, and subsequently stored & how these two layers interact.
- How Speckle treats objects and decomposes them into their constituent parts.
- What Transports are, and why they're so powerful: they allow completely new backends to Speckle to be written and composed.